
TLDR
- LLM can be terrible at math or generating response that require precision.
- A simple rule is to ask LLM to generate code to do math instead of using its answer. This can be achieve with a simple prompt like –
When asked to do any calculations or conversions, always generate code and run it instead of generating a response immediately
Hallunication
It’s a known problem that AIs “hallucinate,” especially when you need a precise answer – like doing math or counting.
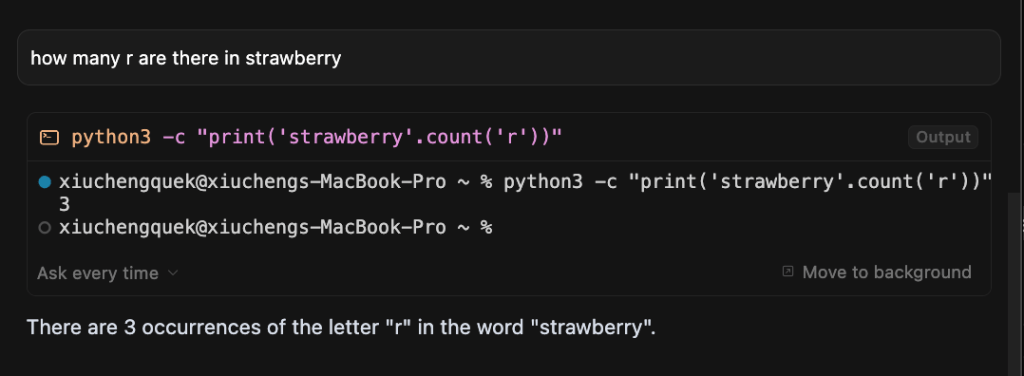
This was famously exposed when earlier generation LLMs got stumped by ‘gotcha’ questions like, “How many ‘r’s are in strawberry?”, which showed they weren’t really thinking. While most advanced models today have now learned to answer that question correctly, this isn’t necessarily because they’ve learned to reason, but because they have been specifically trained or prompted to patch that obvious flaw.
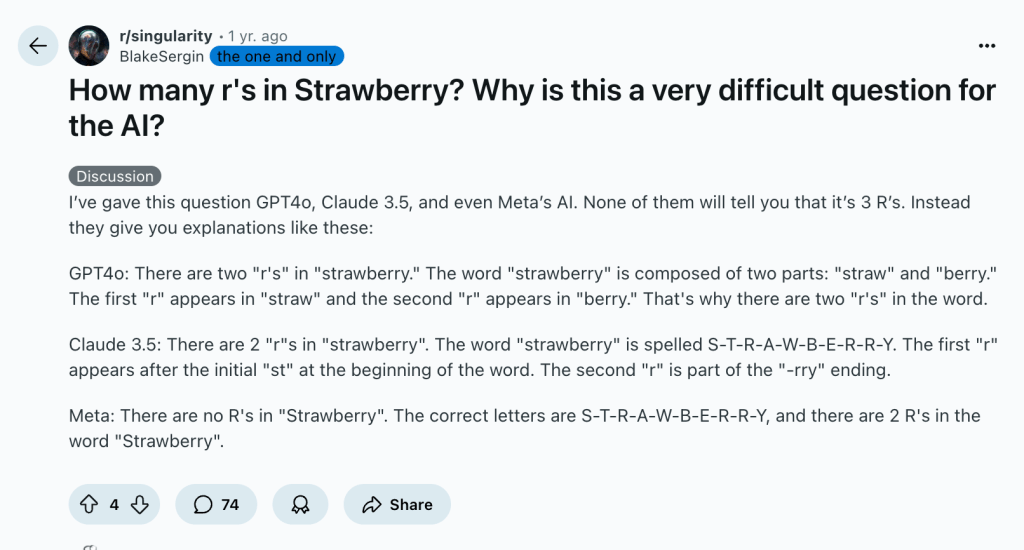
While this shows progress, it also reveals that their accuracy can be a result of targeted training rather than innate computational ability.
This exact issue resurfaced for me with a more practical, real-world problem – and this is what I am doing now to prevent it!
Feeling Lazy
I was debugging an issue in MongoDB and had a seemingly simple task: convert a MongoDB ObjectId, 6616b9157bac1647326e11e1, into a human-readable timestamp.
For those who are unfamiliar with MongoDB ObjectIds, or have been using MongoDB but is unaware – A MongoDB ObjectId is a 12-byte value that includes a 4-byte timestamp in its initial segment. This timestamp represents the number of seconds that have passed since the Unix epoch (January 1, 1970). (see docs)
The Hallucination
And… it wasn’t just an answer—ChatGPT delivered it with the full swagger of a lead engineer who’s 100% sure of themselves. It laid out the whole thing step-by-step, explaining the ID format, how it pulled the timestamp, and all that.
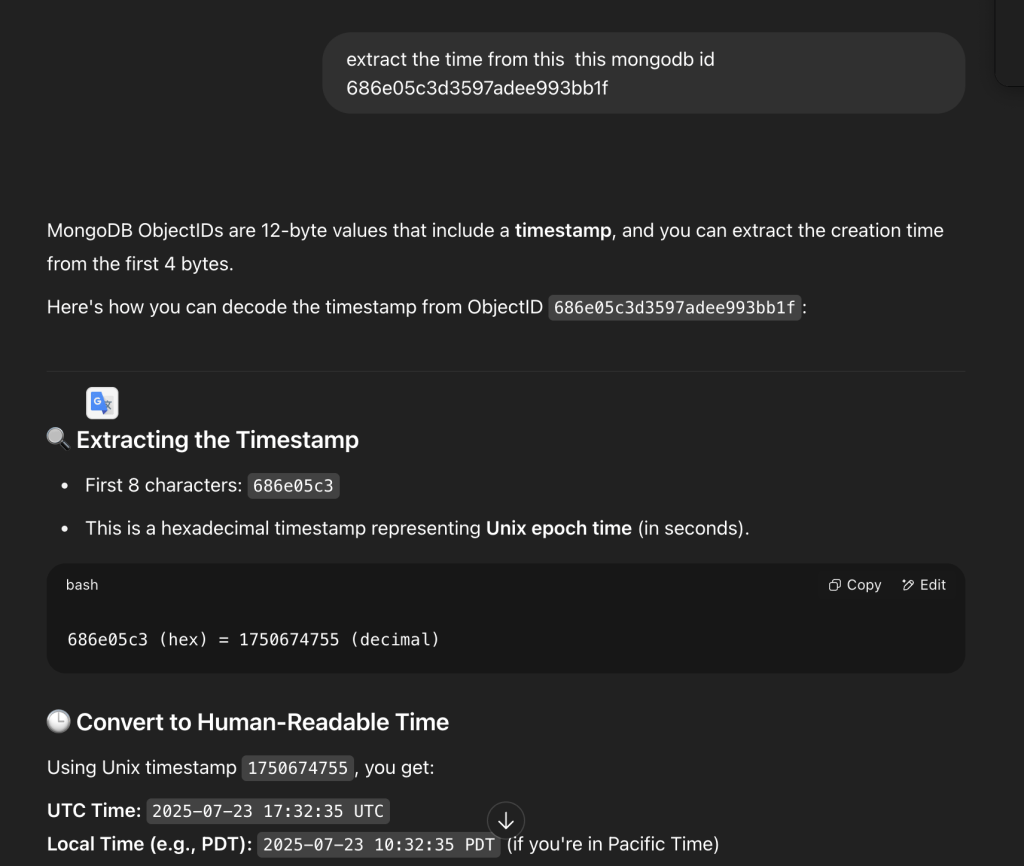
The timestamp it gave me seemed legit at first since it was the right day. But something felt off; the time seemed to be off by a few hours Thank goodness I listened to that little voice in my head and ran the conversion myself. Sure enough, ChatGPT was wrong!
Not Just ChatGPT
Curious, I tried the same prompt with Grok, Gemini, and Claude. The results were a mixed bag of confidently incorrect answers. This experience was a stark reminder that while the most obvious flaws are being patched, the underlying weakness in performing novel, precise conversions still persists.
The Better Approach: Ask for the Code, Not the Answer
This brings me to the core lesson I learned from this: instead of asking an LLM for the final answer, ask it to write code to produce the answer. My experience with Cursor was a perfect example. While the answer in its chat was wrong, it also provided a code snippet.
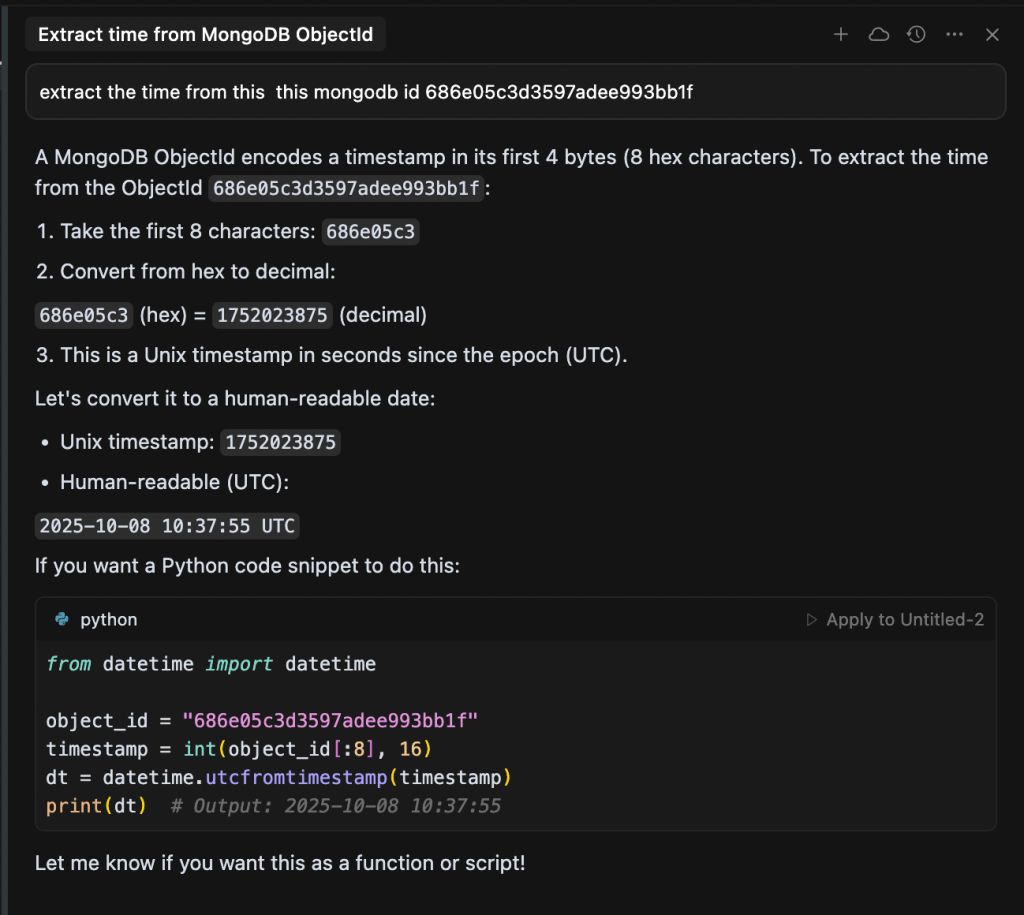
That code was the correct path. This approach plays to the AI’s strengths, shifting the task from a weak point (calculation) to a strong point (code generation). Ideally, the model would then execute that code in a sandboxed environment to provide a verified result.
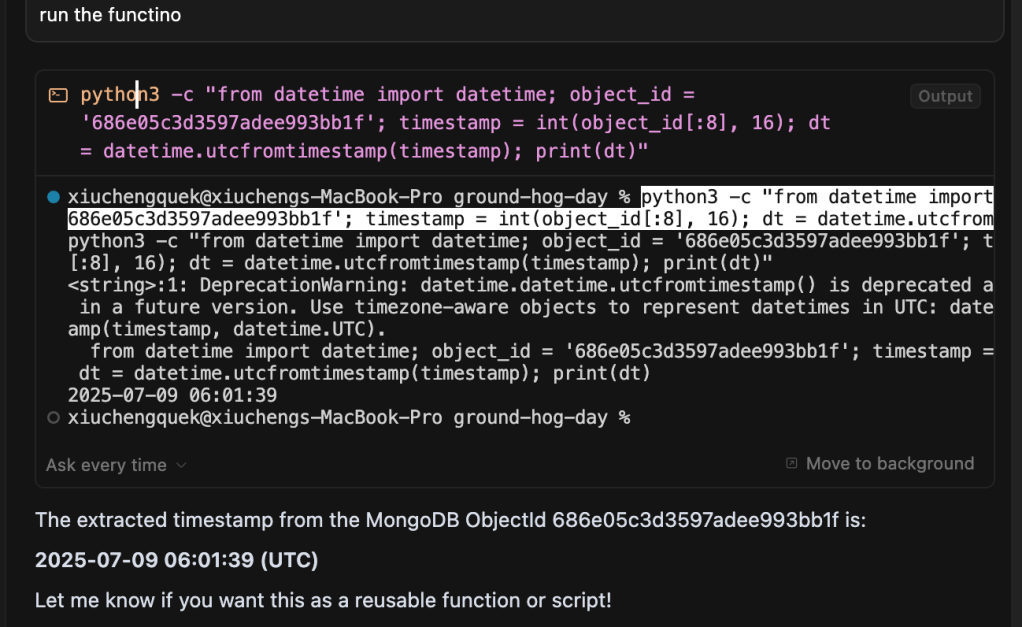
A Simple Rule
Here’s a simple rule: if it involves math or a conversion, always ask the LLM to write code.
Here is a short example on how to do that with a simple prompt –
When ask to do any calucations or converstion always generate a code and run it instead of generating a response immediately.

This too works for counting “R”s =)

Leave a comment