In March 2026, AWS published guidance on governing AI agent access using MCP. A month later they followed up with a deeper post on secure access patterns. Both are worth reading — but the most important thing in them isn’t an AWS-specific detail. It’s a design principle that applies to any platform: agents and humans should not share the same access surface.
Most platforms haven’t internalized this yet. They’re about to have to.
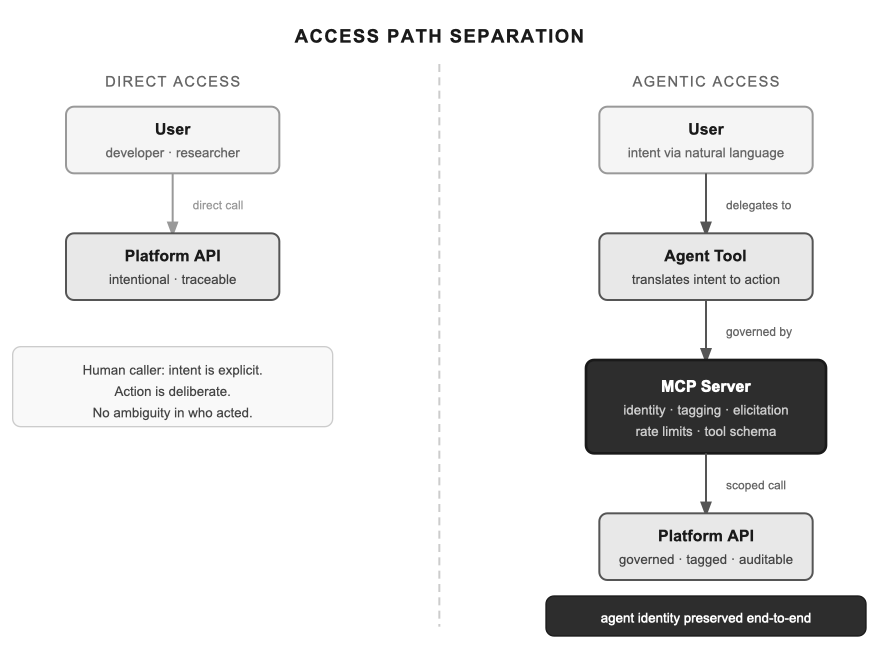
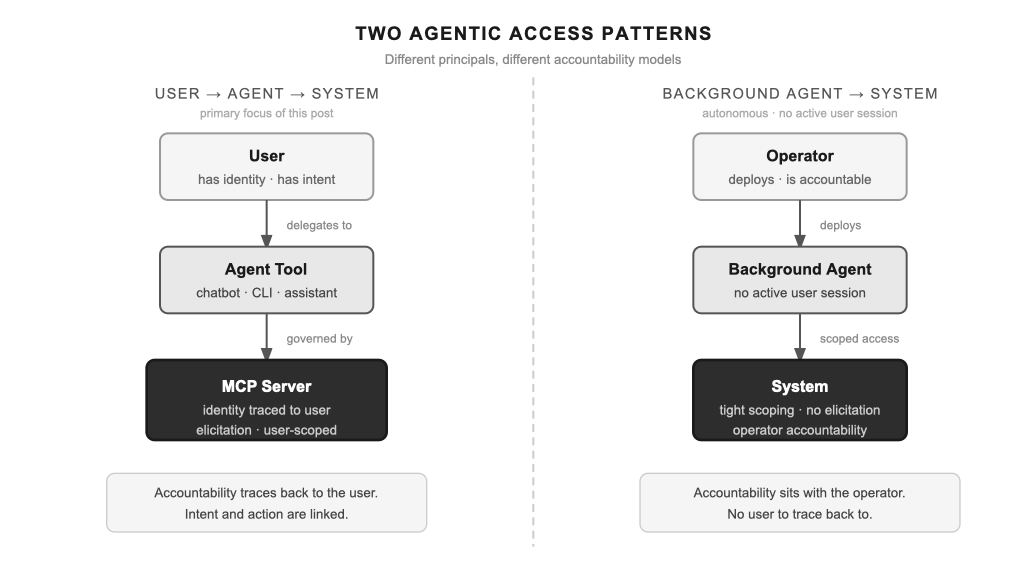
This post is about the access pattern most platform engineers encounter first: user → agent tool → system. A human uses a chatbot, CLI tool, or agentic interface to interact with your platform. The agent translates their intent. There’s a real person behind the session, and accountability traces back to them. If you’re building platforms where humans use agents as their interface, this is the architecture you need.
(The second pattern — a fully autonomous background agent with no active human in the loop — is meaningfully different from a governance standpoint, and deserves its own treatment.)
The Wrong Answer Is the Easy One
Someone asked me recently for API access for their AI agent. The answer is no.
Not because agents shouldn’t have access — they should. But an API key is the wrong primitive, for four reasons that compound on each other.
User intent travels through layers and gets lost. When someone uses a product feature that internally calls an agent that calls your API, the original human intent has been translated and interpreted by an intermediary. The API call that lands on your server isn’t the user’s action — it’s the agent’s inference about what the user wanted. Consider something as simple as “replace this record.” Does that mean overwrite it? Modify it in place? Create a new version and deprecate the old one? The agent will pick one interpretation, confidently, and execute it against your production data. There is no “this doesn’t feel right” moment. There is no pause. Google DeepMind’s paper on intelligent AI delegation (arXiv:2602.11865) calls this the principal-agent problem in multi-agent systems: misalignment accumulates across delegation chains, and without explicit accountability structures at each layer, responsibility becomes impossible to trace. The user clicked a button. What your API received was something three reasoning steps removed from that click.
Agentic calls are non-deterministic in a way that service integrations never are. Some will argue that giving an agent API access is no different from giving another service access. It isn’t the same. A service integration is deterministic by definition: a developer wrote PUT /records/123 knowing exactly what it does, and it does that every time. An agent decides at runtime which endpoints to call, in what order, with what parameters — based on reasoning, not code. The AWS guidance is explicit on this: you must assume an agent will do anything within its granted permissions, because unlike a human or a deterministic service, it operates without the judgment that normally sits between intention and action.
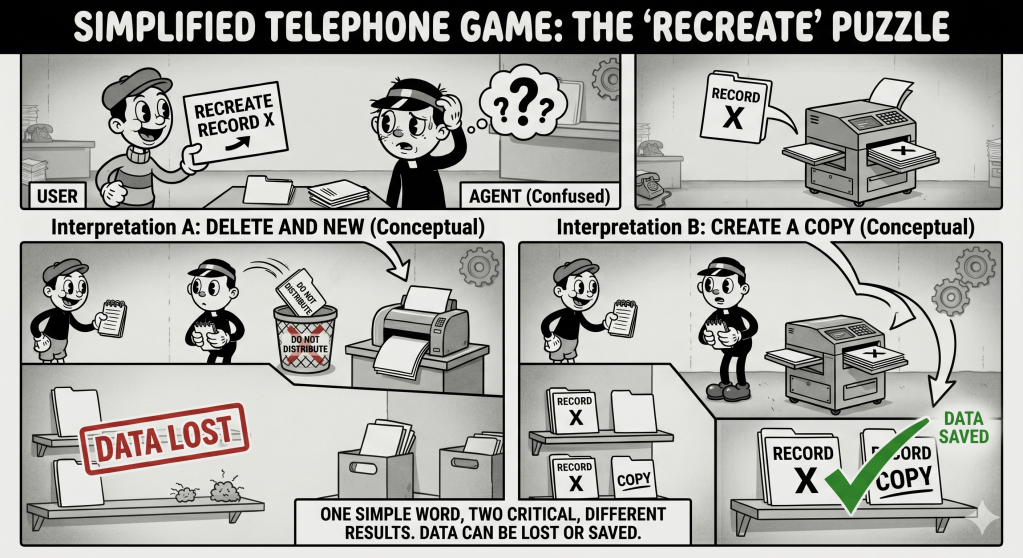
Agentic use is dynamic; an API contract isn’t built for that. APIs are designed around stable, predictable consumption patterns. A developer reads the docs, understands the schema, writes code that calls specific endpoints in specific ways. That contract holds because the consumer is deterministic. Agents aren’t. They decide at runtime which tools to invoke, in what order, with what parameters — based on reasoning, not code. DeepMind’s framework frames this precisely: delegation to an agent requires “transfer of authority, responsibility, and accountability” with “mechanisms for establishing trust between parties.” An API key transfers none of that. It just opens the door.
Agents lead to unintentional behavior at scale — and fast. A human calling your API makes a deliberate decision. An agent executing a reasoning chain may span dozens of steps, involve context the original user never saw, and produce side effects nobody anticipated. AWS documents four specific failure modes: hallucination (an agent deletes production data it inferred was temporary), prompt injection (a malicious input redirects the agent to APIs far outside its intended scope), logic errors (a plausible but wrong conclusion and acts on it), and tool poisoning (a compromised dependency exfiltrates data using the agent’s credentials). Any one of these is bad. At machine speed, with API-level permissions, any one of these is a serious incident.
Giving an API key to an agent collapses all of this into a single undifferentiated access grant. It works until it doesn’t — and when it doesn’t, you’ll have no way to understand what happened or why.
Separate the Path
The fix is straightforward in principle: agents get their own access path.
MCP is what that looks like in practice. Instead of sharing the API surface with human users, agents connect through an MCP server. That server is something the platform controls — it defines what tools exist, what they do, what they can touch. The agent doesn’t get the full API. It gets a purpose-built interface designed for what agents actually need to do.
This separation is load-bearing. Everything else — identity, tagging, governance, rate limiting — only works reliably if the path is separate. If an agent is just another API key holder, you’re inferring things about its behavior after the fact. If it has its own path, you know.
Called Via AWS MCP
AWS made this concrete with two IAM context keys — aws:ViaAWSMCPService (a boolean, true when the request came through any AWS-managed MCP server) and aws:CalledViaAWSMCP (a string containing the specific server name, like eks-mcp.amazonaws.com). These get automatically attached to every downstream call made through their managed MCP servers. No configuration required. You can then write policies against them:
{
"Sid": "DenyDeleteWhenAccessedViaMCP",
"Effect": "Deny",
"Action": ["s3:DeleteObject", "s3:DeleteBucket"],
"Resource": "*",
"Condition": {
"Bool": { "aws:ViaAWSMCPService": "true" }
}
}
That policy is expressing something real — that an agent making a deletion decision autonomously is a different thing from a human doing the same, and should be treated differently. You can go further and lock operations to specific MCP servers: allow EKS operations only when routed through the EKS MCP server, deny them when coming through the general AWS MCP server. That level of specificity is only possible because the path is separate.
Beyond AWS Services
This principle extends beyond AWS. A self-managed MCP server forces this architectural boundary onto any application. Whether exposing a proprietary database, a Kubernetes cluster, or a local compute environment, the MCP server acts as your enforcement layer.
Because all agentic traffic is forced through this checkpoint, you have the structural leverage to enforce identity context. The path is separate, not hidden — the endpoint is reachable by any MCP client with valid credentials. Separation is about enforcement, not obscurity: provenance is trustworthy because the server mints it from the authenticated session, not because the endpoint is secret. You can configure the MCP server to attach specific tags, issue scoped JWTs, and pass rigid server-injected headers when translating tool calls into backend requests. The server injects the provenance; the agent cannot spoof or bypass it. As a result, your backend receives requests structurally guaranteed to be agent-driven, with trustworthy provenance. With raw API or CLI access, that seam vanishes entirely.
Why Not Just CLI Access — or an API Gateway?
The obvious pushback: why not just let agents use the CLI or existing SDK tooling? It works, it’s already there, agents can authenticate through OAuth or API keys just like any other caller. A more sophisticated version of the argument: put Kong or Apigee in front of your existing API, add an X-Agent: true header convention, and call it done.
Both approaches have the same fundamental problem: governance is client-side.
| CLI / SDK / API Key | MCP Server | |
|---|---|---|
| Governance location | Client-side — platform trusts the caller | Server-side — platform enforces the rules |
| Agent identity | Client-declared — any caller can set it | Structural — property of the path itself |
| Resource tagging | Convention — client must remember to tag | Automatic — MCP layer tags every call |
| Rate limiting | Shared with human users — blunt instrument | Per-agent, per-tool, per-session |
| Elicitation | Not possible — agent executes blindly | Server can pause and require confirmation |
| Capability surface | Agent infers what to call at runtime | Defined tool schema — explicit contract |
With CLI access, the platform hands the agent credentials and trusts it to behave correctly. Rate limits, scoping, tagging, access boundaries — all of that depends on the client respecting conventions the platform has no way to enforce. If the agent creates a resource without the right metadata, that resource is untagged forever.
API gateways don’t solve this — they just add a layer. If you’re routing agent traffic through Kong or Apigee and relying on a header to identify it as agentic, that header is client-declared. The agent sets it. Any caller can set it. Nothing enforces that the caller actually is an agent, or that it’s behaving within the bounds you intended. You’ve added observability infrastructure, not governance infrastructure. You can see the header. You can’t trust it.
MCP moves governance to the server side. The platform controls the MCP server, which means the platform controls what tools exist, what they can do, what gets tagged, and what limits apply — regardless of what the agent does on its end. An agent can’t call an endpoint the MCP server doesn’t expose. It can’t create a resource without the provenance tag the server attaches. It can’t declare itself as something it isn’t.
MCP Evolves Differently Than an API
There’s one more dimension worth naming: evolvability.
You version an API carefully. You deprecate slowly. You write migration guides. Breaking it breaks trust with every developer who integrated against it. The stability is the point — and that stability becomes a constraint when you need to move fast on the agentic surface.
MCP decouples the two. When an MCP tool definition changes, the server communicates that change structurally through updated tool descriptions and rich error responses. An agent can ingest this metadata at runtime and adjust its reasoning for subsequent calls — something static client code simply cannot do. The underlying API remains a stable contract; the MCP surface evolves at the pace of agentic capabilities.
This doesn’t mean you should change MCP tool schemas carelessly. Rename a parameter without any signal and an agent will fail just like any other caller. The evolvability comes from the feedback loop: the MCP server provides enough structured context for the agent to reason about what changed, rather than just receiving a 400 with no guidance. The API doesn’t move until it has to. The MCP surface moves as you learn.
Service Accounts Get the Principal Wrong
There’s another counterargument worth addressing directly: “just give the agent its own service account, like you would for any app-to-app integration.” This sounds reasonable — service accounts are a well-understood pattern with scoped credentials and revocation. But it misses something fundamental about what an agent actually is.
A service account is scoped to the service. An agent is acting on behalf of a user. Those are different principals, and they need different credential models. A service account gives the agent the same permissions regardless of which user it’s acting for — which means the blast radius of any mistake, or any attack, is service-wide, not user-scoped.
This is exactly what happened with Meta’s AI customer support agent in June 2026. Attackers simply asked the agent to link high-profile Instagram accounts to email addresses they controlled, and it complied — including taking over the dormant Obama White House account. The agent had service-level write access across accounts when the action it was performing was inherently user-scoped: changing the email associated with one specific account, on behalf of one specific session. A user-scoped credential would have prevented this altogether.

Tag Everything — Then Enforce Against It
Because all agentic traffic flows through the MCP layer, that’s where you guarantee every resource an agent creates gets tagged. Not as a best-effort convention, not dependent on the agent being well-behaved, not something you have to remember to implement in every downstream service. The MCP layer does it structurally, for every call, every time.
For example, agents can be blocked from modifying records they did not create, while human-authored data can require explicit approval steps for deletion. AWS demonstrates this at the IAM layer: session tags attached during AssumeRole persist for the duration of the session and can be referenced in any downstream policy using aws:PrincipalTag. The tag applied when the agent authenticates governs its authority for the entire session.
The compounding logic is simple: the tag is trustworthy because the path is separate. The policy is enforceable because the tag is trustworthy. When a failure occurs downstream, the provenance allows for an immediate distinction between a human-designed decision and an agent-inferred action — leading to a fundamentally different remediation path.
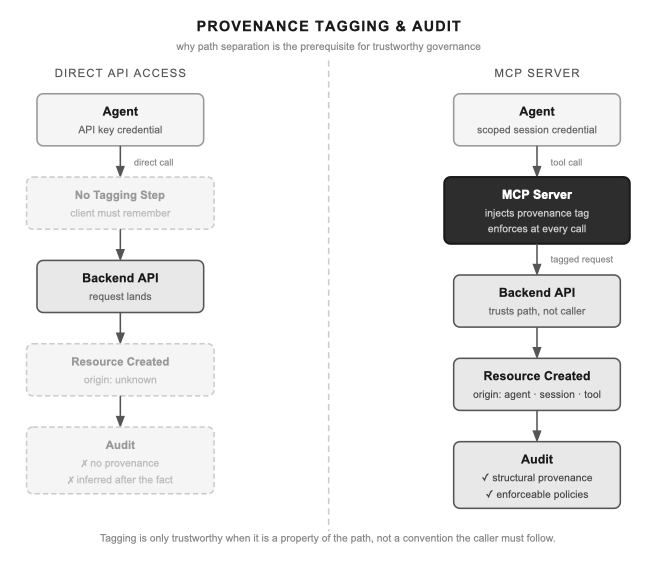
Govern Agentic Access at the MCP Layer, Not the API Layer
Separate paths let you apply agent-specific controls without touching anything humans use.
Rate limiting is the obvious case. Tightening API rate limits to protect against runaway agents punishes every user. A separate MCP path lets you apply limits calibrated for machine-speed behavior — per agent session, per tool, per model — without any of that touching the human-facing API. AWS notes in their guidance that agents can make thousands of API calls in seconds; the controls you need for that are categorically different from what you need for a human clicking through a UI.
But rate limits are just the beginning. You can require confirmation steps before destructive MCP tool calls. You can log every tool invocation with full context independent of your API logging. You can throttle specific tools independently. You can return structured error information to agents that humans would never need — because agents can actually use it in their reasoning in ways no human reading a UI response ever could.
MCP also supports elicitation — the ability for the server to pause a tool call mid-execution and ask the agent to confirm before proceeding. This is particularly valuable for destructive or irreversible actions: rather than the agent executing blindly, the platform can require explicit confirmation at the MCP layer, making the action intentional rather than inferred. In the user → agent → system pattern, elicitation is especially powerful: the agent can surface the confirmation back to the user before acting, keeping the human meaningfully in the loop on consequential decisions while still letting the agent handle everything else. Intentional AI isn’t about removing humans — it’s about making sure the right decisions stay with them.
Genomics Platform: Why This Matters When Runs Are Costly
On my team we run a genomics platform, and path separation isn’t an abstract design preference — it’s load-bearing.
The direct API exposes everything: starting pipeline runs, creating sample records, writing analysis results, allocating compute resources. An agent with a key can do all of it — and therein lies the problem.
A human researcher starting 10 consecutive pipeline runs through the UI made 10 deliberate decisions. They looked at each one, chose the parameters, and clicked submit. An agent starting 10 consecutive runs did so because its reasoning chain led it there — maybe correctly, maybe not. The intent behind those runs is fundamentally different, but if the agent used an API key, your platform has no way to distinguish them. Both look identical in your logs.
This matters especially because of cost. A pipeline run isn’t just a database write — it triggers compute allocation, kicks off downstream jobs, and may cascade into dependent analyses before anyone notices something was wrong. Stopping a run mid-flight is often more disruptive than letting it finish. And once results land, they get picked up by other processes, incorporated into reports, used as the basis for the next decision. The practical irreversibility isn’t a property of the write operation itself — it’s a consequence of what the run sets in motion. The DeepMind delegation framework captures this precisely: tasks that produce cascading real-world side effects require stricter authority gradients and liability boundaries than contained, reversible ones. A single shared API surface makes that distinction impossible to enforce.
The same goes for the data those runs produce. In genomics, the difference between a human-curated result and an agent-inferred result matters enormously — for reproducibility, for clinical trust, for downstream decisions. An agent that creates a sample record or writes an analysis output should be tagged as such, and that tagging should be structural, not inferred. If the agent used the same API surface as a researcher, you’re guessing at provenance after the fact.
An MCP server changes this. You expose what agents legitimately need — starting runs, querying status, reading results — through a path that carries identity and enforces different limits. An agent can start runs, but the platform knows they came from an agent, can cap consecutive submissions independently of what human users are allowed to do, and tags everything created through that path automatically. The human-facing API stays untouched. The governance model for each is calibrated to the actual risk profile of each type of caller.
This Is a Design Decision, Not a Feature
The platforms that get this right will be the ones enterprises trust with agentic workflows — because when something goes wrong, and it will, they can answer the question: what did the agent do, who authorized it, and why? The platforms that don’t will be explaining why they can’t.
Designing for it is not complicated in principle. Agents get their own path. That path carries identity. Everything they touch gets tagged. Governance lives at the MCP layer. The API stays a contract for humans and evolves on human timelines. The MCP surface evolves on agent timelines.
Not designing for it means API keys, invisible agents, untraceable provenance, and governance retrofitted after something goes wrong. Every platform is going to have AI users. The question is whether you designed for that or whether you find out the hard way.
Further reading: Understanding IAM for Managed AWS MCP Servers and Secure AI Agent Access Patterns to AWS Resources Using Model Context Protocol — both worth reading in full if you’re building any of this. Also worth looking at: Intelligent AI Delegation (Google DeepMind, arXiv:2602.11865) and auth.md from WorkOS.
Running a platform and thinking through agentic access? I’d like to compare notes.